06 write a decision tree from scratch
In the last episode, we wrote a nearest neighbor classifier. We will write a decison tree classifier from scratch to show the underlying theory of decition tree algorithm.
We have known that the inner structure of decision tree classifier. It consists of nodes with a True or False question in each node to decide the next node. The process goes on until it goes to a leaf. The leaf contains a label.
Here is examples to learn:
# color | diameter | label
# Green | 3 | Apple
# Yellow | 3 | Apple
# Red | 1 | Grape
# Red | 1 | Grape
# Yellow | 3 | Lemon
If the question can spit examples into two sets with one of them is unmixed set(that contains only one label), we take it as a good question. for example, the queustion “Does the color is Red ?” or “Is the diameter >= 3 ?” will get a set of Grape.
Our goal is to unmix these labels. The trick to building an effective tree is to understand which questions to ask and when.
And to do that, we need to quantify how much a question helps to unmix the labels. And we can quantify the amount of uncertainty at a single node using a metric called Gini impurity. And we can quantify how much a question reduces that uncertainty using a concept called information gain.
We’ll use these to select the best question to ask at each point. The best question is the one that reduces our uncertainty the most.
Gini impurity
And Gini impurity let’s us quantify how much uncertainty there is at a node.
a measure of how often a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset.

information gain
Information gain will let us quantify how much a question reduces that uncertainty.
And it’s just a number that describes how much a question helps to unmix the labels at a node. We will find the question that reduces our uncertainty the most (the biggest information gain).
Note: We’ll take a weighted average of their uncertainty because we care more about a large set with low uncertainty than a small set with high.
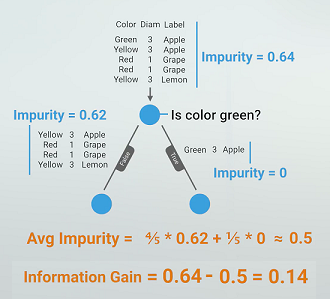
let’s write code from scratch:
raining_data = [
['Green', 3, 'Apple'],
['Yellow', 3, 'Apple'],
['Red', 1, 'Grape'],
['Red', 1, 'Grape'],
['Yellow', 3, 'Lemon']
# ['Orange', 3, 'Lemon']
]
testing_data = [
['Green', 3, 'Apple'],
['Yellow', 3, 'Apple'],
['Red', 1, 'Grape'],
['Red', 1, 'Grape'],
['Yellow', 3, 'Lemon']
]
header = ["color", "diameter", "label"]
def class_count(rows):
counts = {}
for row in rows:
label = row[-1]
if label not in counts:
counts[label] = 0
counts[label] += 1
return counts
# print(class_count(training_data))
def is_numeric(s):
try:
float(s)
return True
except ValueError:
return False
class Question:
def __init__(self, column, value):
self.column = column
self.value = value
def match(self, example):
val = example[self.column]
if is_numeric(val):
return val >= self.value
else:
return val == self.value
def __repr__(self):
condition = "=="
if is_numeric(self.value):
condition = ">="
return 'Is %s %s %s ?' % (
header[self.column], condition, str(self.value)
)
# print(Question(1, 3))
# print(Question(0, 'Green'))
def partiton(rows, question):
true_rows, false_rows = [], []
for row in rows:
if question.match(row):
true_rows.append(row)
else:
false_rows.append(row)
return true_rows, false_rows
# true_rows, false_rows = partiton(training_data, Question(0, 'Red'))
# print(true_rows, false_rows)
def gini(rows):
counts = class_count(rows)
impurity = 1
for label in counts:
p = counts[label] / float(len(rows))
impurity -= p ** 2
return impurity
# no_mixing =[['Apple'], ['Apple']]
# print(gini(no_mixing))
# some_mixing = [['Apple'], ['Orange']]
# print(gini(some_mixing))
# some_mixing = [['Apple'], ['Orange'], ['Lemon']]
# print(gini(some_mixing))
def info_gain(left, right, current_uncertainty):
p = float(len(left)) / (len(left) + len(right))
return current_uncertainty - p * gini(left) - (1-p) * gini(right)
def find_best_split(rows):
best_gain = 0
best_question = None
current_uncertainty = gini(rows)
n_features = len(rows[0]) - 1
for col in range(n_features):
values = set([row[col] for row in rows])
for val in values:
question = Question(col, val)
true_rows, false_rows = partiton(rows, question)
if len(true_rows) == 0 or len(false_rows) == 0:
continue
gain = info_gain(true_rows, false_rows, current_uncertainty)
if gain >= best_gain:
best_gain, best_question = gain, question
return best_gain, best_question
# best_gain, best_question = find_best_split(training_data)
# print(best_gain, best_question)
class Decision_Node:
def __init__(self, question, true_branch, false_branch, impurity, gain):
self.question = question
self.true_branch = true_branch
self.false_branch = false_branch
self.gain = gain
self.impurity = impurity
class Leaf:
def __init__(self,rows):
self.rows = rows
self.prediction = rows[0][-1]
def build_tree(rows):
gain, question = find_best_split(rows)
if gain == 0:
return Leaf(rows)
true_rows, false_rows = partiton(rows, question)
true_branch = build_tree(true_rows)
false_branch = build_tree(false_rows)
impurity = gini(rows)
return Decision_Node(question, true_branch, false_branch, impurity, gain)
def print_tree(node, spacing=""):
if isinstance(node, Leaf):
print(spacing + "Predict", node.prediction)
return
print(spacing + str(node.question) +
' (impurity = %s)' % str(node.impurity) +
' (gain = %s)' % str(node.gain))
print(spacing + '--> True')
print_tree(node.true_branch, spacing + " ")
print(spacing + '--> False')
print_tree(node.false_branch, spacing + " ")
def classify(row, node):
if isinstance(node, Leaf):
return node.prediction
if node.question.match(row):
return classify(row, node.true_branch)
else:
return classify(row, node.false_branch)
my_tree = build_tree(training_data)
print('the tree is:')
print_tree(my_tree)
class MyDecisionTreeClassifier:
def fit(self, X_train, y_train):
rows = []
for i in range(len(y_train)):
rows.append(X_train[i] + [y_train[i]])
self.my_tree = build_tree(rows)
def predict(self, tests):
predictions = []
for row in tests:
label = classify(row, self.my_tree)
predictions.append(label)
return predictions
# get data set
import numpy as np
a = np.array(training_data, dtype=np.dtype(object))
l = a[0].size
X_train = a[:, :l-1].tolist()
y_train = a[:, l-1].tolist()
myclassifier = MyDecisionTreeClassifier()
myclassifier.fit(X_train, y_train)
predictions = myclassifier.predict(testing_data)
print(testing_data)
print(predictions)
# the following is to run the script:
(base) D:\learning\machine learning\ML recipes\codes>python mydecisiontree.py
the tree is:
Is diameter >= 3 ? (impurity = 0.6399999999999999) (gain = 0.37333333333333324)
--> True
Is color == Yellow ? (impurity = 0.4444444444444445) (gain = 0.11111111111111116)
--> True
Predict Apple
--> False
Predict Apple
--> False
Predict Grape
[['Green', 3, 'Apple'], ['Yellow', 3, 'Apple'], ['Red', 1, 'Grape'], ['Red', 1, 'Grape'], ['Yellow', 3, 'Lemon']]
['Apple', 'Apple', 'Grape', 'Grape', 'Apple']
(base) D:\learning\machine learning\ML recipes\codes>